
In questa guida vedremo come imbastire un piccolo progetto .NET Core Azure Functions che interroghi una base dati SQL Server utilizzando lo strumento Entity Framework per l’interrogazione.
Prima però un piccolo accenno di teoria.
Che cos’è Azure Functions?
Citando la documentazione ufficiale Microsoft, Azure Functions è una soluzione serverless (priva di server) che permette di scrivere poco codice di programmazione, mantenendo il minimo di infrastruttura server e risparmiando così costi.
In sostanza, chi utilizza Azure Functions si occupa solo della mera parte di programmazione, il resto, per esempio la preparazione dell’hardware, l’aggiornamento software e/o il mantenimento in esecuzione del tutto, viene gestito dall’infrastruttura cloud Azure.
Caso d’uso reale
Abbiamo bisogno di un processo, schedulato giornalmente, che si occupi del controllo di determinati record all’interno di una base dati accessibile in rete e, successivamente, al verificarsi di determinate condizioni sui record controllati, invii una e-mail di servizio ad un indirizzo preimpostato.
Tradizionalmente, senza utilizzare Azure Functions, una volta terminata la fase di scrittura del codice della procedura sopra, lo sviluppatore si troverà nella condizione di scegliere una strada per la pubblicazione del servizio: macchina fisica in rete 24 ore su 24 in ufficio, VPS a noleggio mensile di qualche provider, ecc… Successivamente dovrà gestire la configurazione di tutta l’infrastruttura e la sua manutenibilità futura: aggiornamenti S.O., aggiornamenti hardware, ecc.… Tutti aspetti che influiscono sui tempi, sui costi e sul know-how di lavoro.
Utilizzando Azure Functions, lo sviluppatore scrive il codice della funzione, pubblica su una risorsa Azure direttamente da Visual Studio. La funzione è in rete e funzionante nell’immediato.
Vediamo ora i passaggi per ottenere questa immediatezza.
Requisiti
- Visual Studio con gli strumenti Azure installati (in questa guida viene utilizzata la versione 2019);
- SQL Server per la base dati (in questa guida viene utilizzata la versione Express 2019).
Il progetto di esempio
Ricapitolando, data una base di dati con informazioni anagrafiche, la funzione Azure che scriveremo dovrà processare tutte le anagrafiche inserite non ancora processate e, successivamente, impostarle come processate utilizzando un campo di FLAG che chiameremo Readed.
Creiamo quindi un nuovo database, nel nostro caso azure_function_example, ed una nuova tabella, Users, con al suo interno quattro campi:
- Id – UNIQUEIDENTIFIER – NOT NULL – PRIMARY KEY
- FirstName – NVARCHAR(MAX) – NOT NULL
- LastName – NVARCHAR(MAX) – NOT NULL
- Readed – BIT – NOT NULL – DEFAULT 0
CREATE TABLE [dbo].[Users](
[Id] [uniqueidentifier] NOT NULL,
[FirstName] [nvarchar](max) NOT NULL,
[LastName] [nvarchar](max) NOT NULL,
[Readed] [bit] NOT NULL,
CONSTRAINT [PK_Users] PRIMARY KEY CLUSTERED
(
[Id] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, OPTIMIZE_FOR_SEQUENTIAL_KEY = OFF) ON [PRIMARY]
) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY]
GO
ALTER TABLE [dbo].[Users] ADD CONSTRAINT [DF_Users_Readed] DEFAULT ((0)) FOR [Readed]
GO
Popoliamo la tabella con qualche record di esempio, impostando per tutti il campo FLAG Readed a FALSE (0):
| Id | FirstName | LastName | Readed |
| 8530B138-5F43-437F-8854-268E5D2E1C50 | Paolo | Gialli | 0 |
| 4794C833-F277-419D-BECA-5E59D3DF9AE2 | Antonio | Verdi | 0 |
| 80405F8B-651B-438B-A8C2-B7B82E8E78CA | Mario | Rossi | 0 |
| 323C2A9A-5BEF-4EB3-A951-D40533B74A01 | Stefano | Bianchi | 0 |
Nota: gli identificativi univoci sono stati generati casualmente utilizzando lo strumento https://www.guidgenerator.com/.
La funzione
Proseguiamo ora con la creazione del progetto .NET. Apriamo Visual Studio ed all’interno della procedura guidata di creazione di un nuovo progetto, selezioniamo la voce “Funzioni di Azure“:
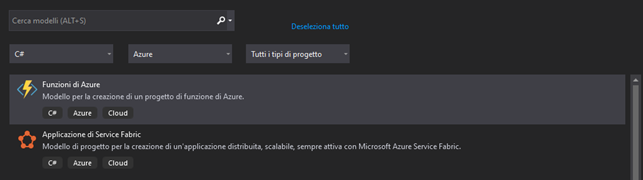
Nota: la voce non è presente se durante l’installazione di Visual Studio non vengono installati anche gli strumenti Azure.
Successivamente, eseguiamo la configurazione di base del progetto:
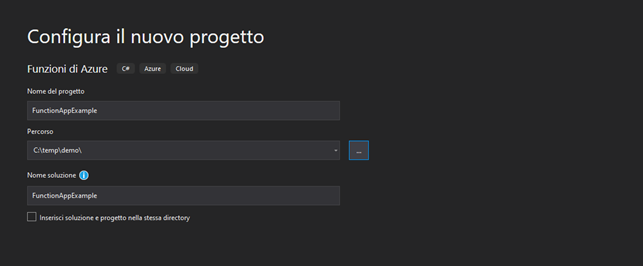
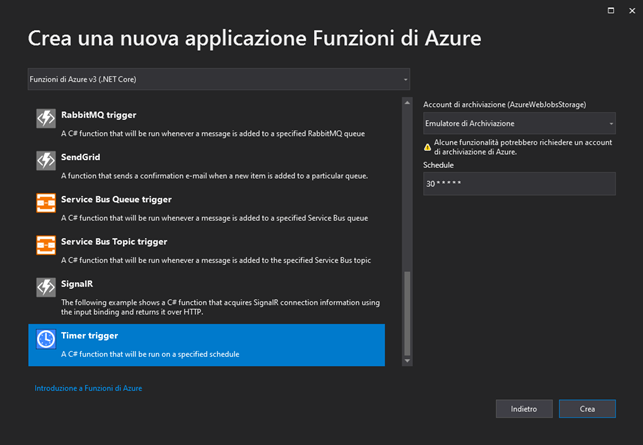
Selezioniamo dal menu a discesa (schermata superiore) “Funzioni di Azure v3 (.NET Core)“. Timer trigger per eseguire la funzione in modalità schedulata ed impostiamo, nella casella a sinistra dell’elenco, l’espressione NCRONTAB “30 * * * * *” per indicarne le regole di schedulazione. In questo caso la funzione verrà eseguita il trentesimo secondo di ogni minuto, di ogni ora, di ogni giorno, di ogni mese e di ogni anno.
Nota: potete approfondire la libreria NCronTab e le regole delle espressioni NCRONTAB al seguente indirizzo https://docs.microsoft.com/it-it/azure/azure-functions/functions-bindings-timer?tabs=csharp#ncrontab-expressions.
Dopo aver creato il progetto verrà aperta la funzione, chiamata Function1 di default:
[FunctionName("Function1")]
public static void Run([TimerTrigger("30 * * * * *")]TimerInfo myTimer, ILogger log)
{
log.LogInformation($"C# Timer trigger function executed at: {DateTime.Now}");
}
Eseguendo il codice, otteniamo il seguente risultato:
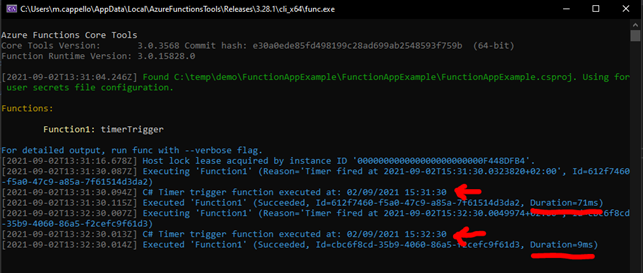
Come da schedulazione, il trentesimo secondo di ogni minuto viene stampato sul terminale il metodo LogInformation richiamano dalla funzione. Possiamo notare come il log, molto dettagliato, ci fornisce in autonomia anche l’indicazione del tempo di esecuzione della funzione ed il suo nome, nel caso c’è ne sia presente più di una per esempio.
Aggiungiamo ora al progetto i pacchetti EntityFramework necessari dal gestore di pacchetti NuGet:
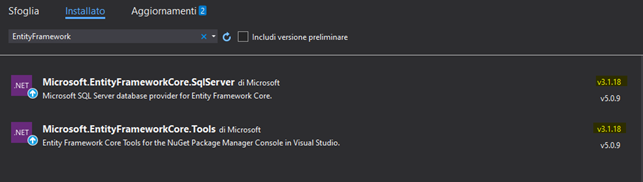
Nota: Azure Functions v3 utilizza .NET Core 3.1, è importantissimo quindi installare EntityFrameworkCore.SqlServer 3.1.x e non l’ultima versione 5 disponibile per motivi di compatibilità con alcune librerie referenziate di EntityFramework non compatibili con la versione .NET Core del progetto.
Installiamo anche EntityFramworkCore.Tools per poter utilizzare il comando Scaffold-DbContext per generare automamente la classe di Context e i modelli della base dati creata in precedenza.
Posizioniamoci quindi all’interno della “Console di Gestione pacchetti” e lanciamo il comando per eseguire lo Scaffold:
Scaffold-DbContext "Data Source=SERVER_SQL;Initial Catalog=azure_function_example;Integrated Security=True;" Microsoft.EntityFrameworkCore.SqlServer -Context ExampleContext -OutputDir Models -ForceAl termine dell’esecuzione della procedura, verrà creata una nuova cartella Models all’interno della cartella principale del progetto, con all’interno il file Users.cs che identifica il modello della tabella Users della base dati:
public partial class Users
{
public Guid Id { get; set; }
public string FirstName { get; set; }
public string LastName { get; set; }
public bool Readed { get; set; }
}
All’interno della cartella viene creato anche il file ExampleContext.cs (ExampleContext perchè indicato all’interno del comando di Scaffold) che fornisce il Context per collegarsi ed effettuare operazioni sul database.
Torniamo ora alla funzione Function1 ed apportiamo le modifiche al codice come segue:
[FunctionName("Function1")]
public static void Run([TimerTrigger("30 * * * * *")]TimerInfo myTimer, ILogger log)
{
using (var ctx = new ExampleContext())
{
var users = ctx.Users.Where(u => !u.Readed).ToList();
if(users.Count > 0)
{
foreach (var user in users)
{
// process user...
// ...
// mark user as readed
user.Readed = true;
ctx.Users.Update(user);
log.LogInformation($"User {user.FirstName} readed!");
}
ctx.SaveChanges();
}
}
}Le modifiche apportate avviano una nuova istanza ExampleContext (non impostando una stringa di connessione, viene utilizzata di default quella indicata all’interno del comando di Scaffold), viene ottenuto successivamente l’elenco degli utenti con il campo FLAG Readed impostata a FALSE e viene scorsa la lista ottenuta nel caso sia presente almeno un’utente.
Ogni volta che un’utente viene processato, viene impostato il campo FLAG Readed a TRUE.
Lanciamo in esecuzione la funzione con le nuove modifiche apportate ed osserviamo il risultato:
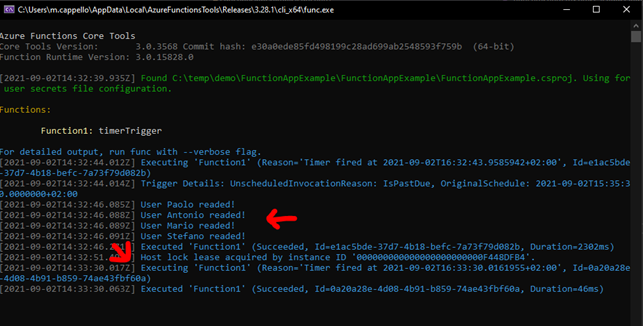
Come si può leggere dal log, nella prima esecuzione vengono processati tutti e quattro i record presenti nella base dati (FLAG Readed a FALSE), nella seconda esecuzione invece non viene processato nulla.
Dando uno sguardo alla base dati, successivamente all’esecuzione della funzione:

Tutti e quattro i record hanno il campo FLAG Readed impostato a TRUE, correttamente processati dalla funzione.
Conclusione
Come abbiamo visto, la creazione di una funzione schedulata periodicamente, che esegue operazioni su una base dati, è molto semplice e veloce con l’utilizzo di Azure Functions e Visual Studio.
Inoltre questo tipo di approccio semplifica anche l’eventuale pubblicazione futura su di una sottoscrizione Azure grazie alle procedure guidate di Visual Studio:
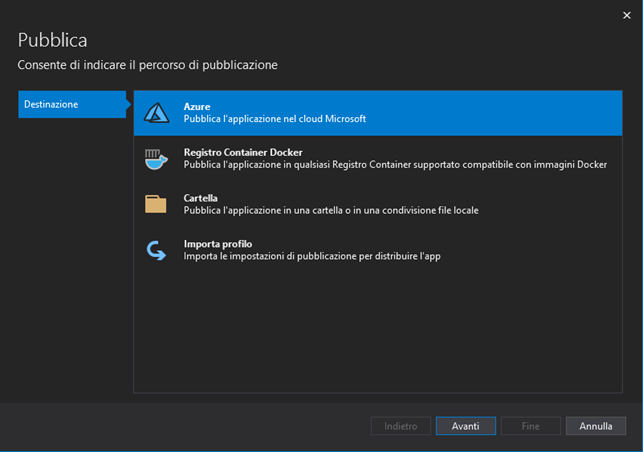
Senza ombra di dubbio la soluzione migliore per chi vuole spendere tutto il proprio tempo nella scrittura ed ottimizzazione del codice, senza pensare all’infrastruttura o ad altro.
Link Utili
Potete scaricare il progetto di esempio qui.
https://docs.microsoft.com/en-us/azure/azure-functions/functions-overview
Pingback: Creare e testare una Azure Functions su MacOS con VSCODE | Fontana Marco IT Consulting