
I file di log sono spesso fonte di problemi, perché ad esempio presentano formati strani, perché sono accessibili solo connettendosi sulle singole macchine o perché nel corso degli anni andando verso un approccio legato ai microservizi, il numero di log delle applicazioni è sensibilmente aumentato, rendendone più difficile la gestione.
Lo stack ELK (o Elastic Stack) è una soluzione robusta che consente di migliorare la ricerca, la gestione e l’analisi dei dati, log compresi.
ELK sta diventando la più comune piattaforma open source di gestione dei log utilizzata a livello globale. I framework open source Elasticsearch, Logstash e KIbana, si combinano per fornire una piattaforma unica per l’archiviazione, il recupero, l’ordinamento e l’analisi dei dati.
Logstash ha il compito di raccogliere, analizzare, normalizzare, aggregare e indicizzare i dati (in vari formati e tipologie) provenienti da più server e di memorizzarli in un unico storage per facilitare ulteriori possibili trasformazioni e lavorazioni; in seguito alle trasformazioni i dati vengono spediti a varie destinazioni di output supportate
Elasticsearch (ES) è un server di ricerca ed analisi, basato su Apache Lucene, altamente scalabile che consente di immagazzinare, ricercare ed analizzare grandi volumi di dati con interrogazioni che avvengono quasi in tempo reale.
Per questi motivi è divenuto nel tempo molto popolare nell’ambito Big Data, negli ambienti enterprise e nel settore del cloud computing. Ad oggi è il secondo motore di ricerca più popolare ed è usato in progetti come Netflix, Facebook, Wikipedia, Atlassian, Github e altri.
I dati in Elasticsearch vengono memorizzati in uno o più indici. Un indice è una raccolta di file che presentano caratteristiche tra loro simili. Poiché chi lavora con Elasticsearch in genere si occupa di grandi volumi di dati, i dati in un indice vengono a loro volta suddivisi in frammenti (“shards”) per rendere lo storage più gestibile. Un indice potrebbe essere troppo grande per adattarsi a un singolo disco, ma i frammenti sono più piccoli e possono essere allocati su nodi diversi in base alle esigenze; un altro vantaggio è che le ricerche possono essere eseguite in diversi frammenti in parallelo, accelerando così l’elaborazione delle query.
Kibana è il motore di visualizzazione dei dati di Elasticsearch che offre agli utenti la possibilità di analizzare e visualizzare i dati. Permette un’interazione nativa con tutti i dati presenti nello storage attraverso dashboard personalizzate; queste dashboard sono dinamiche, salvabili, condivisibili ed esportabili. E’ possibile eseguire facilmente analisi di dati avanzate e visualizzare i dati in una varietà di tabelle, istogrammi e mappe.
Attorno a questo ecosistema, gravitano anche i Beats; è questa introduzione che ha portato lo stack ELK a essere conosciuto anche come Elastic Stack. Beats è una famiglia di log shipper open source che vengono installati sui diversi server della nostra infrastruttura e agiscono come agenti leggeri per la raccolta di log e metriche per diversi casi d’uso. Mentre le metriche mostrano le tendenze e le propensioni di un servizio o di un’applicazione, lo scopo dei log è quello di preservare quante più informazioni possibili, per lo più tecniche, su un evento specifico. Ognuno dei Beats ha il suo compito, possono ad esempio collezionare file di log relativi a eventi di sistema, ricavare informazioni sui database, fare sniffing della rete, raccogliere informazioni sulle risorse, analizzare gli eventi di Windows.
Il numero dei Beats è in continua crescita poichè sviluppati sia da Elastic che dalla community; ecco alcuni dei pricipali:

Il loro compito è dunque quello di raccogliere i dati delle macchine in cui risiedono e di inoltrarli a Logstash, se hanno bisogno di essere elaborati o analizzati, oppure direttamente ad Elasticsearch.
In questa guida installeremo Filebeat, tra i Beats è quello più utilizzato ed è indicato per raccogliere e inviare file di log e altri dati. Uno dei motivi che rendono Filebeat così efficiente è il modo in cui gestisce la contropressione: se Logstash è occupato, Filebeat rallenta la velocità di lettura e riprende il ritmo una volta terminato il rallentamento.
Filebeat può essere installato su quasi tutti i sistemi operativi, anche come contenitore Docker e include anche moduli interni per piattaforme specifiche come Apache, MySQL, Docker, MariaDB, Percona, Kafka e altro.
Perchè lo Stack ELK è conveniente?
- è semplice in quanto offre un’interfaccia utente elegante ed intuitiva che semplifica le attività di analisi dei dati.
- è flessibile poichè è possibile configurarlo in modo che accetti i dati da una varietà di fonti in continuo aumento, aggiunte sotto forma di plugin.
- è gratuito, per la maggior parte delle funzionalità, i pacchetti sono installabili sotto licenza Apache 2.0.
Cosa faremo?
L’obiettivo è quello di raccogliere syslog provenienti da più server in un’unica posizione centralizzata.
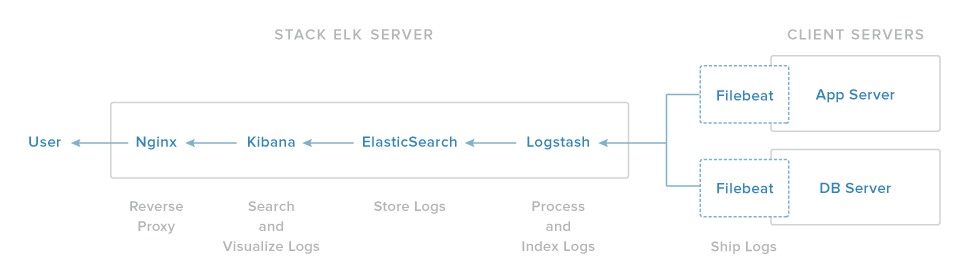
La nostra configurazione dello prevede l’installazione dei seguenti componenti:
- Java: è richiesto da Elasticsearch e Logstash
- Elasticsearch: il componente che memorizzerà tutti i log
- Kibana: l’ interfaccia Web che consentirà la ricerca e la visualizzazione dei log, che verrà inviata tramite proxy a Nginx
- Nginx: configurato come proxy inverso per Kibana
- Logstash: il componente server di Logstash che elaborerà i log in entrata
- Filebeat: installato sui server client che invieranno i propri log a Logstash.
Prerequisiti
Per questo tutorial, utilizzeremo due macchine virtuali Linux con le seguenti specifiche:
- Sistema operativo: Ubuntu Server 18.04
- RAM: 4 GB CPU: 2
- indirizzo IP: 10.1.10.126
- hostname: serverelk
La quantità di CPU, RAM e memoria richiesta dal server ELK dipendono dal volume di log che si intende raccogliere.
Oltre al server su cui installeremo lo stack ELK, dovremo ovviamente disporre di altre macchine su cui installeremo Filebeat per raccogliere i log:
- Sistema operativo: Ubuntu Server 18.04
- RAM: 4 GB CPU: 2
- indirizzo IP: 10.1.10.129
- hostname: clientelk
Colleghiamoci alla macchina serverelk e iniziamo la configurazione dello stack.
Colleghiamoci all’utente root per avere tutti i privilegi necessari per eseguire la nostra configurazione utilizzando il comando:
sudo su1.Installazione Java
Elasticsearch richiede Java 8. Installeremo la JDK 1.8 con il seguente comando:
sudo apt install openjdk-8-jre-headlessAl termine dell’installazione, controllare la versione di java.
java -versionJava 1.8 risulterà installato.
2.Installazione di Elasticsearch
Dopo aver installato Java, installeremo il primo componente di Elastic Stack: Elasticsearch.
Aggiungiamo la chiave pubblica GPG di Elasticsearch e il repository di Elastic.
wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" | sudo tee -a /etc/apt/sources.list.d/elastic-7.x.list
Ora aggiorniamo il repository e installiamo il pacchetto di Elasticsearch usando i seguenti comandi.
sudo apt updatesudo apt install elasticsearch -y
Al termine dell’installazione, rechiamoci nella directory ‘/ etc / elasticsearch’ e modifichiamo il file di configurazione ‘elasticsearch.yml’.
vim /etc/elasticsearch/elasticsearch.ymlLimitiamo l’accesso esterno all’istanza di Elasticsearch.
Scommentiamo (rimuovendo #) le righe “network.host” e “http.port” per la configurazione della porta di default utilizzata da elasticsearch.
network.host: localhost
http.port: 9200
Salva ed esci premendo Esc e digitando :wq! seguito dal tasto Invio.
Ora avviamo il servizio elasticsearch e lo abilitiamo per fare in modo che si avvii automaticamente ad ogni avvio del sistema.
systemctl start elasticsearch
systemctl enable elasticsearch
Ora elasticsearch è attivo e funzionante, possiamo controllare utilizzando i comandi di seguito. Con il comando netstat otterremo la porta predefinita ‘9200’ su cui elastichsearch è in ascolto. Con il curl otterremo invece informazioni sulla versione di elasticsearch che abbiamo installato.
netstat -plntucurl -XGET 'localhost:9200/?pretty'
L’installazione di elasticsearch è stata completata.
3.Installazione di Kibana
Il secondo componente da installare è Kibana. Installeremo la dashboard di Kibana dal repository elastic e configureremo il servizio kibana per l’esecuzione sull’indirizzo localhost.
Installiamo la dashboard di Kibana usando il comando apt qui sotto.
sudo apt install kibana -yOra modifichiamo il file di configurazione ‘kibana.yml’.
vim /etc/kibana/kibana.ymlScommentiamo le righe relative a ‘server.port’, ‘server.host’ e ‘elasticsearch.url’.
server.port: 5601 server.host: "localhost" elasticsearch.url: "http://localhost:9200"
Questa impostazione fa in modo che Kibana sia accessibile solo all’host locale. Nei prossimi passaggi configureremo Nginx per consentire l’accesso esterno.
Salva ed esci.
Ora avviamo il servizio kibana e abilitiamolo per avviarsi ogni volta all’avvio del sistema.
sudo systemctl enable kibanasudo systemctl start kibana
L’installazione della dashboard di Kibana è stata completata.
4.Installa Nginx come Reverse-Proxy per Kibana
Poiché abbiamo configurato Kibana per renderlo accessibile solo su localhost, dovremo configurare Nginx come reverse-proxy per consentire l’accesso esterno. In questo modo, digitando l’ip del nostro server sul browser di un computer locale, andremo a interrogare Nginx sulla porta 80 che a sua volta ci reindirizzerà sulla porta 5601 dove Kibana è in ascolto.
Installa Nginx e i pacchetti ‘apache2-utils’ sul sistema.
sudo apt install nginx apache2-utils -yCon il comando htpasswd creeremo l’ autenticazione di base per accedere alla dashboard di Kibana. Nel nostro caso cloudsurfers sarà il nome del nostro utente, .
sudo htpasswd -c /etc/nginx/.kibana-user cloudsurfersInseriamo la password da utilizzare quando richiesto e confermiamo premendo invio. Non dimenticate queste credenziali perchè saranno necessarie per accedere alla dashboard di Kibana.
Ora, rechiamoci nella directory di configurazione ‘/ etc / nginx’ e crea un nuovo file host virtuale chiamato ‘kibana’.
vim /etc/nginx/sites-available/kibanaCopia la seguente configurazione dell’host virtuale Nginx di seguito. Accertati che server_name corrisponda al nome del tuo server.
server {
listen 80;
server_name 10.1.10.126;
auth_basic "Restricted Access";
auth_basic_user_file /etc/nginx/.kibana-user;
location / {
proxy_pass http://localhost:5601;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection 'upgrade';
proxy_set_header Host $host;
proxy_cache_bypass $http_upgrade;
}
}
Salva ed esci.
Dopo aver inserito la password, attiviamo l’host virtuale di kibana e rimuoviamo la configurazione di default.
ln -s /etc/nginx/sites-available/kibana /etc/nginx/sites-enabled/rm /etc/nginx/sites-enabled/default
Testiamo tutta la configurazione di nginx con il comando seguente:
nginx -tSe non ci sono errori, possiamo avviare il servizio Nginx e abilitarlo per avviarlo automaticamente ad ogni avvio del sistema.
systemctl enable nginx
systemctl restart nginx
L’installazione e la configurazione di Nginx come reverse proxy per la dashboard di Kibana sono state completate.
5.Installa Logstash
Installeremo Logstash per centralizzare i log sul nostro server e permettere l’elaborazione dei dati raccolti. Come accennato in precedenza, sarebbe possibile inviare dati direttamente ad Elasticsearch se questi non richiedono trasformazioni.
Utilizziamo il seguente comando:
sudo apt install logstash -y
La configurazione è composta da tre sezioni: input, filtri e output. Configureremo Logstash per accettare in ingresso nel nostro server i log provenienti dalle altre macchine client tramite Filebeat; imposteremo un filtro per raccogliere solo i dati che ci interessano e configureremo l’output affinchè venga creato l’indice in Elasticsearch per consentire la ricerca dei dati raccolti.
I file di configurazione di Logstash sono in formato JSON e andranno creati in /etc/logstash/conf.d.
Creiamo un file di input chiamato filebeat-input.conf e :
vim /etc/logstash/conf.d/filebeat-input.confImpostiamo come nostro input “filebeat” attraverso la seguente configurazione:
input {
beats {
port => 5044
}
}
Questo file specifica il beats in input che comunicherà con Logstash sulla porta tcp 5044.
Salva ed esci.
Creiamo ora un file di configurazione che fungerà da filtro per Logstash denominato syslog-filter.conf.
vim /etc/logstash/conf.d/syslog-filter.confCon la seguente configurazione verranno ricercati da Filebeat solo i log che sono etichettati come ‘syslog’, per renderli strutturati e interrogabili.
filter {
if [type] == "syslog" {
grok {
match => { "message" => "%{SYSLOGTIMESTAMP:syslog_timestamp} %{SYSLOGHOST:syslog_hostname} %{DATA:syslog_program}(?:\[%{POSINT:syslog_pid}\])?: %{GREEDYDATA:syslog_message}" }
add_field => [ "received_at", "%{@timestamp}" ]
add_field => [ "received_from", "%{host}" ]
}
date {
match => [ "syslog_timestamp", "MMM d HH:mm:ss", "MMM dd HH:mm:ss" ]
}
}
}
Salva ed esci.
Configuriamo infine l’output di Elasticsearch “output-elasticsearch.conf”.
vim /etc/logstash/conf.d/output-elasticsearch.confLa seguente configurazione imposta logstash per conservare i dati di Filebeat in Elasticsearch (in ascolto sulla port 9200), in un indice che prenderà il nome del beat utilizzato (filebeat nel nostro caso) seguito dalla data di creazione.
output {
elasticsearch {
hosts => "localhost:9200"
sniffing => true
manage_template => false
index => "%{[@metadata][beat]}-%{+YYYY.MM.dd}"
document_type => "%{[@metadata][type]}"
}
}
Salva ed esci.
Testeremo la configurazione di Logstash con il seguente comando:
sudo -u logstash /usr/share/logstash/bin/logstash --path.settings /etc/logstash -t
Se non ci sono errori di sintassi, dovrebbe essere visualizzato il seguente messaggio Config Validation Result: OK . In caso di errori, prova a leggere l’output dell’errore per vedere cosa c’è che non va nella configurazione. Puoi anche controllare il file di log di logstash con il seguente comando:
tail -f /var/log/logstash/logstash-plain.log
Al termine, avviare il servizio logstash e abilitarlo l’avvio automatico.
sudo systemctl enable logstash
sudo systemctl start logstash
Controllare che il servizio logstash sia attivo usando il comando systemctl.
systemctl status logstashIl servizio Logstash è ora attivo e funzionante.
L’installazione dello Stack-ELK è stata completata.
Ora sarà necessario installare Filebeat sulle macchine client e configurarlo per inoltrare i dati a Logstah.
6.Installa Filebeat
In questo passaggio, configureremo il client Ubuntu 18.04 “clientelk” installando su di esso Filebeat. Colleghiamoci quindi al server “clientelk” con privilegi di root e prima di installare Filebeat nel sistema, modifichiamo il file hosts utilizzando l’editor di vim.
sudo su vim /etc/hosts
Aggiungiamo indirizzo ip e nome del nostro serverelk.
10.1.10.126 serverelk
Salva ed esci.
Successivamente aggiungiamo anche qui la chiave e il repository di Elastic.
wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" | sudo tee -a /etc/apt/sources.list.d/elastic-7.x.list
Aggiorna il repository e installa il pacchetto “filebeat” utilizzando il comando apt di seguito.
apt update apt install filebeat -y
Al termine dell’installazione, procediamo con la configurazione di Filebeat modificando il file “filebeat.yml”.
vim /etc/filebeat/filebeat.yml
Ora abilitiamo la configurazione di input modificando il valore della riga “enabled” da “false” a “true” e definiamo i percorsi dei file di log di sistema da inviare al server logstash. Per questa guida, aggiungeremo i log di ssh “auth.log” e i syslog.
# Change to true to enable this input configuration.
enabled: true
# Paths that should be crawled and fetched. Glob based paths.
path:
- /var/log/auth.log
- /var/log/syslog
Poichè i dati andranno inviati a Logstash per le elaborazioni, commentiamo l’output predefinito relativo ad Elasticsearch e decommentiamo la riga di output di Logstash come di seguito.
#output.elasticsearch: # Array of hosts to connect to. # hosts: ["localhost:9200"]
output.logstash: # The Logstash hosts host: ["serverelk:5044"]
Salva ed esci.
Successivamente, dobbiamo modificare il file ‘filebeat.reference.yml’ per abilitare i moduli filebeat che ci interessano.
vim /etc/filebeat/filebeat.reference.yml
Abilitiamo il modulo di sistema syslog per filebeat scommentando le righe come di seguito.
- module: system # Syslog syslog: enabled: true
Salva ed esci. Abilitare il modulo con il seguente comando:
filebeat modules enable system
Per visualizzare l’elenco dei moduli abilitati e di quelli disponibili possiamo utilizzare il comando:
filebeat modules list
L’installazione e la configurazione di Filebeat sono state completate. Possiamo controllare che tutto sia configurato correttamente compreso l’output per verificare che la connessione al server vada a buon fine. Utilizziamo i comandi:
filebeat test config filebeat test output
Se vengono mostrati errori controllate la sintassi dei file di configurazione modificati in precedenza.
Se è tutto OK il prossimo step sarà quello di caricare in Elasticsearch l’indice necessario per Filebeat e in Kibana le dashboard necessarie per visualizzare correttamente i file di log e tutti i job di machine learning.
sudo filebeat -e
Ora avviamo il servizio di Filebeat e abilitiamolo per l’avvio automatico.
systemctl start filebeat systemctl enable filebeat
Controlla il servizio Filebeat utilizzando i comandi seguenti.
systemctl status filebeat tail -f /var/log/filebeat/filebeat
I log shipper di filebeat sono attivi e comunicano con il serverelk sulla porta 5044.
Test
Apriamo un browser web e colleghiamoci al nostro server digitando l’indirizzo IP. Apparirà la finestra di autenticazione in cui andremo ad inserire i dati dell’utente creato al punto 4.

Se le credenziali sono corrette verrà caricata la dashboard dello stack.
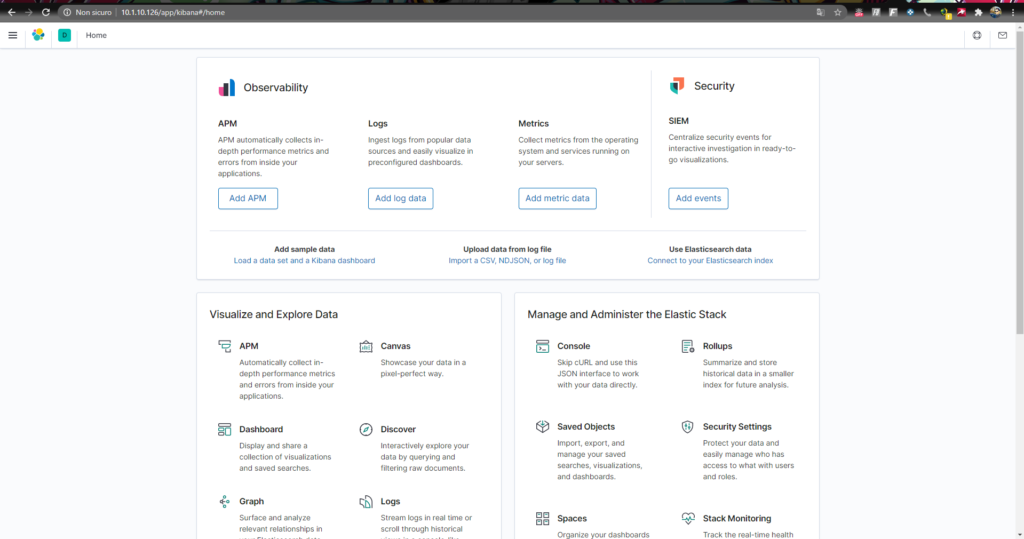
Apriamo il menu laterale e selezioniamo Stack Management. Kibana utilizza patterndi indice per recuperare i dati dagli indici di Elasticsearch.
Definiamo il pattern di “filebeat- *” e clicchiamo sul pulsante “>Next Step”
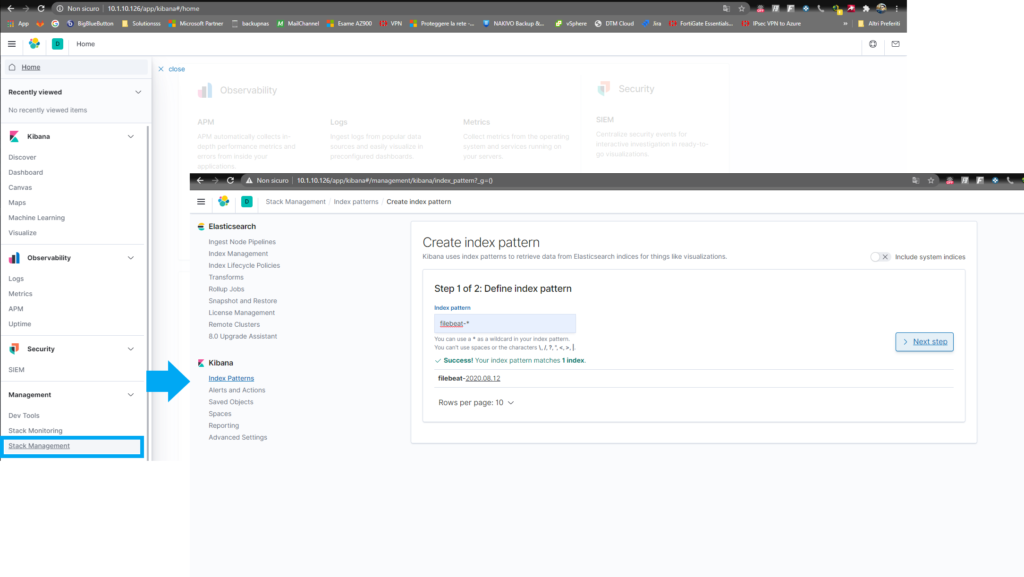
Selezioniamo @timestamp per ordinare i risultati in vase alla data e clicca su Create Index Pattern.
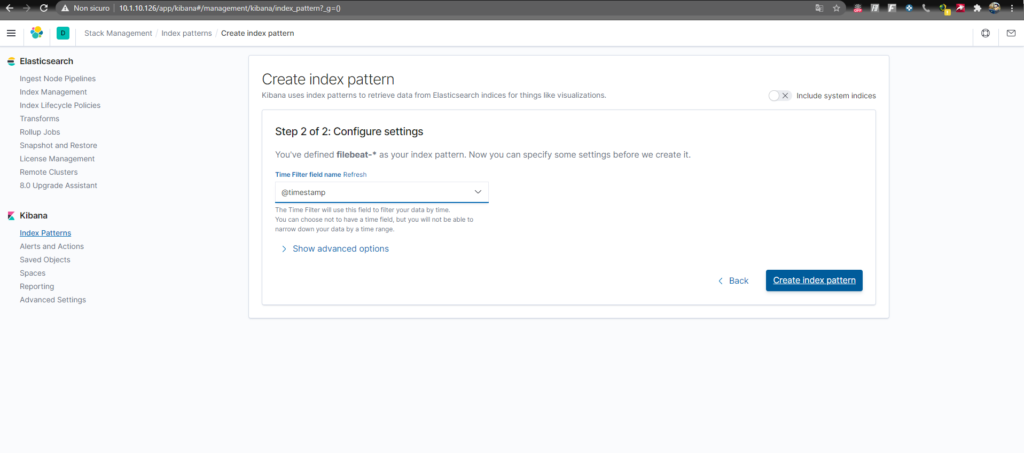
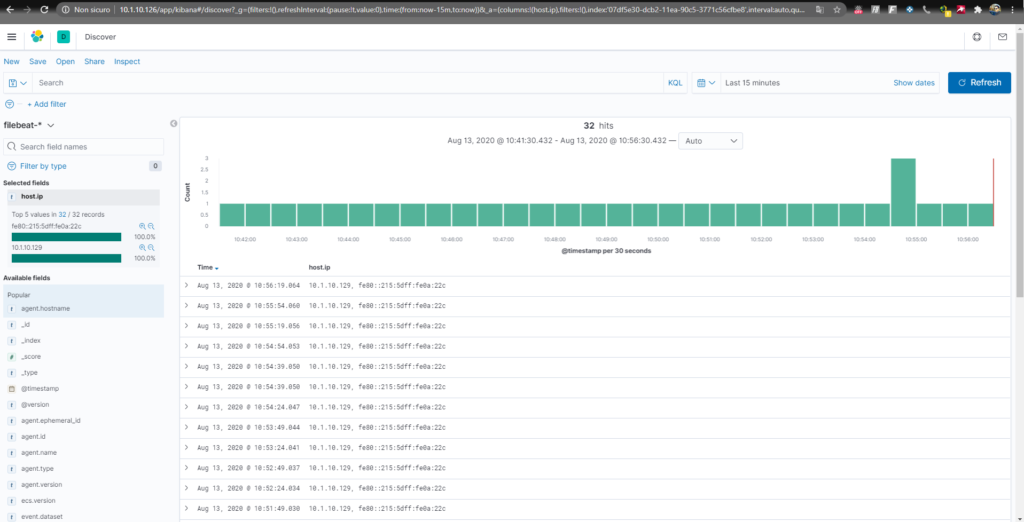
Torniamo nella Home e facciamo clic “Discover”. Selezioneremo l’indice predefinito di Filebeat e questo ci mostrerà tutti i dati di log inviati dal nostro server “clientelk”
Conclusioni
Lo stack ELK può essere sicuramente utile in moltissime situazioni in cui si tenta di identificare problemi di sistema o malfunzionamenti di applicazioni, poiché consente di cercare in tutti i log di un determinato server. È inoltre utile perché consente di individuare anche i problemi che si estendono su più server, filtrando e correlando tutti i log generati durante un determinato intervallo di tempo. Grazie ai numerosi plugin aggiuntivi in continuo aumento è possibile mettere in piedi una soluzione ad hoc per ogni tipo di esigenza
Link Utili & Credits
- Documentazione Elastic https://www.elastic.co/guide/index.html
- Best practice indici Elasticsearch https://logz.io/blog/managing-elasticsearch-indices/
- English Tutorial https://www.howtoforge.com/tutorial/how-to-install-elastic-stack-ubuntu-1804/