
Nell’articolo del mese scorso “Storicizzazione del dato, compressione e interrogazione di strutture dati JSON in SQL Server” abbiamo analizzato, sia in termini prestazionali che in termini di peso, la storicizzazione del dato utilizzando gli strumenti JSON introdotti con SQL Server 2016. Abbiamo anche toccato la tematica della compressione e successivamente dell’interrogazione del dato compresso.
Quel tipo di approccio affrontato lo possiamo chiamare approccio ibrido in quanto utilizza una base dati relazionale, SQL Server per l’appunto, per salvare dei dati in un formato struttura non relazionale, JSON nel nostro caso.
E se avessimo affrontato la stessa tematica utilizzando uno strumento creato appositamente per la gestione di strutture non relazionali?
Vediamo una piccola analisi utilizzando, con la stessa base dati dell’articolo precedente, CosmosDB restando quindi sempre in casa Microsoft.
Premessa
La base dati utilizzata è la stessa dell’articolo del mese scorso, un set di 100 mila record con una struttura JSON nidificata su più livelli.
Tutte le interrogazioni e quindi i numeri che vedremo, sono eseguite sulla medesima macchina utilizzata precedentemente, ricapitolando:
- Laptop Lenovo X1 Carbon 6a generazione
- Intel i7-8550U
- 16GB di memoria RAM LPDDR3
- SSD Samsung
Per la base dati NoSQL è stato utilizzato il software Azure Cosmos DB Emulator che permette di avere un’istanza CosmosDB locale di test prima di lavorare direttamente su Azure in cloud.
Inoltre questa analisi non vuole presentarsi come una guida passo passo per l’utilizzo di Azure CosmosDB. Risulta utile per dare qualche spunto di riflessione in merito all’argomento. In più utilizzando una sintassi SQL-like, noterete come il “porting” delle query di interrogazione utilizzate precedentemente sia estremamente semplice da rendere molto intuitivo il passaggio da SQL Server a CosmosDB.
Migrazione dei dati
La base dati utilizzata è un database SQL Server con una tabella chiamata “TabellaInChiaro” composta da due campi: Id, chiave primaria intera numerica, ed un campo chiamato Json di tipo NVARCHAR(MAX).
La tabella è popolata con 100 mila record ed all’interno del campo Json di ciascun record è presente una struttura JSON nidificata su più livelli.
Iniziamo quindi a predisporre la nuova base dati NoSQL, avviamo CosmosDB Emulator e creiamo un nuovo database, nel nostro caso chiamato dbtest:
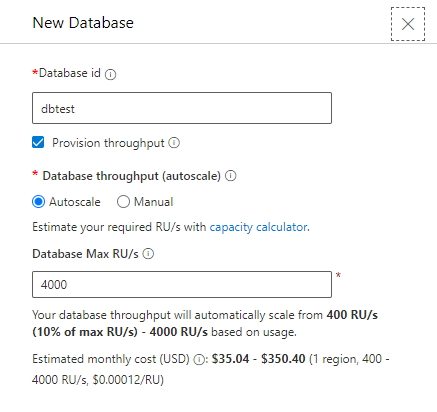
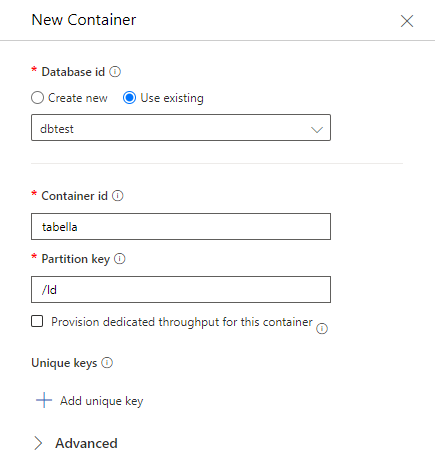
Aggiungiamo alla base dati un nuovo container, che nel nostro caso chiamiamo “tabella“, ed indichiamo una chiave di partizione che chiamiamo “id“:
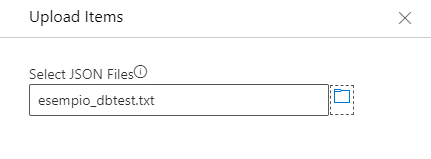
Ora partendo dalla base dati SQL Server dobbiamo creare un file JSON strutturato come la struttura finale che vorremmo ottenere per i nostri record (item su CosmosDB) ed importarlo dalla sezione Upload Items:
Alternativamente all’importatore tramite pagine Web, è possibile utilizzare lo strumento Azure DocumentDb Migration Tool, open source, questo risulta molto più veloce rispetto all’importazione da pagina Web come mostrato sopra.
Nota personale: per la creazione del file JSON da importare, ho trovato molto comodo l’utilizzo dello strumento FOR JSON PATH, questo permette di formattare i risultati di una query SQL in formato JSON e quindi con un po’ di manipolazione sui dati, permette di arrivare al file di importazione molto comodamente.
Al termine dell’importazione ci troveremo davanti la nostra base dati NoSQL:
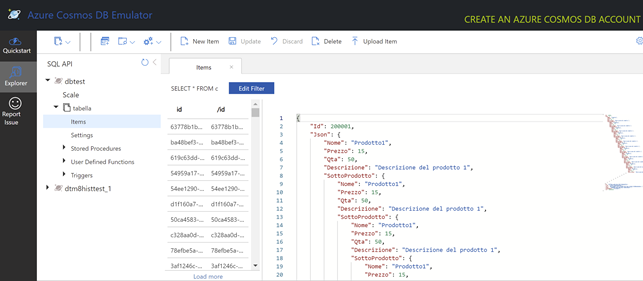
Dimensioni
Andiamo ad analizzare le dimensioni totali della tabella (container su CosmosDB):
| TabellaInChiaro (megabyte) | Azure CosmosDB (megabyte) |
| 316 | 146 |
La differenza è netta, la base dati NoSQL essendo ottimizzata per strutture non-relazionali gestisce al meglio il peso del dato su disco risultando praticamente il doppio più leggero rispetto allo stesso dato su SQL Server.
Prestazioni
Vediamo ora le prestazioni di interrogazione del dato, prima con una query SQL che utilizza lo strumento OPENJSON, successivamente con la stessa query utilizzando però JSON_VALUE su SQL Server (per la differenza dei due strumenti potete fare riferimento a questo articolo).
OPENJSON
SELECT Nome FROM TabellaInChiaro CROSS APPLY OPENJSON([Json]) WITH (Nome NVARCHAR(MAX))| SQL Server (ms) | Azure CosmosDB (ms) |
| 2617 | 534 |
JSON_VALUE
SELECT JSON_VALUE([Json], '$.Nome') FROM TabellaInChiaro| SQL Server (ms) | Azure CosmosDB (ms) |
| 595 | 534 |
Utilizzando lo strumento JSON_VALUE ed interrogando il primo livello della struttura JSON, non c’è differenza nella velocità di interrogazione del dato.
Passiamo ora ad una query più complessa che interroghi più elementi nidificati:
SELECT P.Nome, P.Prezzo, P.Qta, T.Nome, T.Prezzo, T.Qta FROM TabellaInChiaro CROSS APPLY OPENJSON([Json]) WITH (Nome NVARCHAR(MAX), Prezzo INT, Qta INT, SottoProdotto NVARCHAR(MAX) AS JSON) P CROSS APPLY OPENJSON(SottoProdotto) WITH (Nome NVARCHAR(MAX), Prezzo INT, Qta INT, SottoProdotto NVARCHAR(MAX) AS JSON) Tla stessa query su CosmosDB diventa:
SELECT c.Json.Nome, c.Json.Prezzo, c.Json.Qta,
c.Json.SottoProdotto.Nome AS NomeSottoProdotto, c.Json.SottoProdotto.Prezzo AS PrezzoSottoProdotto,
c.Json.SottoProdotto.Qta AS QtaSottoProdotto FROM c| SQL Server (ms) | Azure CosmosDB (ms) |
| 6345 | 514 |
Conclusioni
Partiamo con il dire che Azure CosmosDB essendo uno strumento dedicato e specifico per questo tipo di gestione del dato non relazionale, sia in termini di peso che in termini di prestazioni ha un’ottimizzazione notevolmente maggiore rispetto a SQL Server.
Differenza comunque non troppo marcata con SQL Server (JSON_VALUE) se si effettuano interrogazioni semplici su un unico livello di nidificazione, qui i due strumenti sembrano equivalersi.
Storia che invece cambia nettamente effettuando interrogazioni complesse in cui vengono prese in esame strutture nidificate su più livelli. Differenze marcate anche a livello di peso come visto sopra.
Concludendo, ogni metodo ha i suoi pro e i suoi contro, questa piccola analisi non serve per decretare un vincitore, ma per mettere in luce le differenze concrete dei due strumenti utilizzando una stessa base dati. Facendo un esempio, in sistemi preesistenti può essere migliore l’accoppiata SQL Server e strumenti JSON per evitare di aggiungere punti di rotture e sfruttare la base dati esistente evitando un collegamento con una base dati esterna. In progetti nuovi al contrario, per avere uno spazio e una velocità di interrogazione più efficiente, può essere un bene adottare fin da subito una base dati non relazionale NoSQL piuttosto che il classico DB SQL Server. Ad ognuno la propria scelta.
Link Utili
https://docs.microsoft.com/it-it/azure/cosmos-db/local-emulator?tabs=ssl-netstd21
https://www.microsoft.com/en-us/download/details.aspx?id=46436